LRU
最近最少使用(Least Recently Used) ,加入新的将最少使用的元素淘汰掉
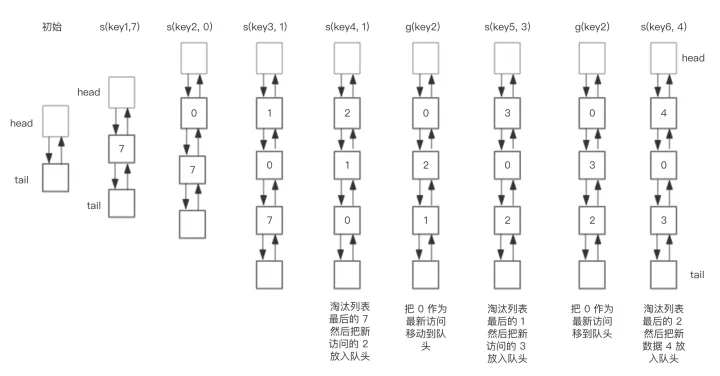
两种操作:
- 当访问时,如果有就将访问的挪到头
- 当加入时,将新的挪到头,如果链表满了,将尾移除
O(1)操作头尾元素,用双向链表,O(1)时间访问用哈希表
手搓双向链表实现:
class LRUCache { |
优雅的STL版本:
class LRUCache { |
TopK
字面意思,就是求无序数组的第k大的数
最大值最小值
先从寻找最大值最小值开始,直接遍历也就是O(n)的时间复杂度。
伪代码:
min = A[1] |
TopK
- 在这里我们找第 k 小的数
- 利用快速排序的partition思想
- 当partition分出来的 i < k 时,也就是我们找到第 i 小的数,我们需要在 i + 1 ~ n中找第k小的数。当 i > k 时,我们需要在 1 ~ i - 1中找第k小的数。
- 如果 i == k 说明刚好找到
- partition 的思想就是让 i 左边的数都小于 i 右边的数都大于 i ,不care i 左右两边内部的顺序,只care i 的位置。
期望时间复杂度为O(n),假设每次都是刚好分半, 有可能还更小 T(n) + T(n/2) + T(n/4) +… T(1) 也就是等积数列求和为 T(2n) 所以为O(n)
最坏情况为O(n^2),如果很不幸每次都是找到一组的最大元素进行partition 就会造成 T(n) + T(n - 1) + T(n - 2) + .. T(1) 的情况 最后为T(n^2),所以用random划分来尽可能地避免该情况
伪代码:算法导论中第七章的快排的partition十分优雅,可以看看
|